
Notes on My Research Taste
From isolated models to measured systems

Over the last few years, my understanding of what it means to do “good” research has changed significantly. This post is not a set of rules or best practices, but a record of what I’ve learned through building things that eventually had to work under real constraints. Many of my earlier ideas looked strong in isolation and weak in systems. What follows is how those experiences reshaped my research taste, how I decide what to work on, how I measure progress, and when I stop.

Two years ago, my research approach was largely opportunistic. I patched problems with ideas that felt innovative in isolation, taking a bottom-up path with little structure, no explicit design, and no measurement model to support robust evaluation. My goal was simple: solve a narrowly scoped problem using something I had seen elsewhere or drawn inspiration from. In hindsight, this kind of work is relatively easy to validate externally, especially through conference reviews (it’s largely diluted), because it optimizes for local novelty rather than system-level impact.
At the time, I was focused on being clever: proposing new algorithms, architectures, or training objectives, and incrementally improving existing work. What I failed to do was step back and understand the system my solution was meant to live in. I rarely questioned whether the surrounding constraints, hardware, data, latency, or integration would ultimately shape or even invalidate the idea. Those goals haven’t disappeared, but my research taste has shifted. Today, I care less about isolated cleverness and more about whether an idea survives contact with the system it’s embedded in.
I joined Owl Autonomous Imaging in Jan’25 as an MLE Intern. Within the first two months, I worked on two of their most challenging problems: stereo calibration for RGB–thermal cameras and multimodal image fusion. Both solutions were technically strong. The fusion models exceeded prior baselines by a wide margin, around 20% in detection and 25% in segmentation, and the stereo calibration achieved reprojection errors below 1.5 pixels, which is considered solid for RGB–thermal pairing.
The next step was deployment. These models needed to run on an in-house chip (developed by the hardware team) as well as an NVIDIA Jetson platform, alongside the rest of the autonomy stack. Under a strict 100 ms latency budget, the system had to execute stereo calibration, multi-sensor fusion across two RGB cameras, two thermal cameras, LiDAR, IMU, and GNSS, followed by perception and SLAM. That’s where my “research” approach failed miserably.
When the Model met the System
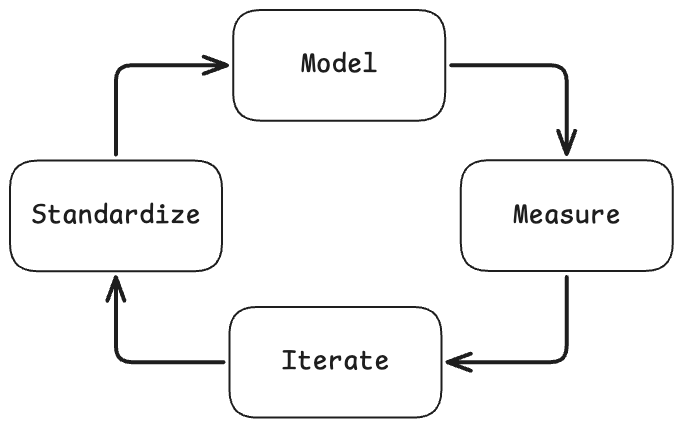
If I’m improving models in isolation, I’m not pushing the performance of the models to the limits of hardware and physics. I need to co-design algorithms, training, and systems together. In reflecting on my problem-solving habits, I reverse-engineered the ‘skeleton’ of my research taste. I find that my most effective work follows a distinct four-step lifecycle, essentially codifying my research taste into a repeatable framework in a closed-loop system:
Model: I begin by building a prototype defined by strict objectives and system constraints (grounded in a mathematical model)
Measure: I develop a measurement model (inspired by the physics way of doing things) to comprehensively observe and record all prototype parameters.
Iterate: I refine the system based strictly on the data gathered from those observations (execute a feedback loop driven by the measure data)
Standardize: I use the logs from the iteration phase to dictate the design of the final evaluation suite.
I expect most ideas to fail once they are exposed to real system constraints. In fact, I consider early failure a success, but only if it tells me why something doesn’t work. How can I define a useful failure? The one that measurably violates a constraint or exposes a mismatch between my objective and the system’s behavior. There’s no need to treat failure as a signal to immediately “optimize harder.” Instead, it should tell me whether I am optimizing the wrong abstraction. If an approach collapses under latency, memory, numerical stability, or distribution shift, I assume the issue lies in the formulation, not in insufficient tuning. My goal is to surface these failures ASAP, with instrumentation in place, so that I can either reformulate the problem or discard the idea with confidence.
I want the plot of model quality vs efficiency first; the leaderboard comes later. Improving performance means rethinking training, evaluation, or representation rather than just scaling parameters.
Data as a first-class system component
I treat data not as a static input, but as an active component of the system. Before changing a model, I ask whether the observed failure mode is actually a data problem. Many performance issues (instability, brittleness, poor downstream transfer) are better addressed by reshaping the data distribution than by increasing the model capacity. In practice, this means I examine coverage across difficulty regimes, identify underrepresented or overly dominant patterns, and evaluate whether the training and evaluation data reflect the operational environment. If the model struggles in specific contexts, I prefer targeted data interventions: reweighting, resampling, or generating counterexamples, before architectural changes.
A better model trained on the wrong data is still the wrong solution.
Now, I’ll simulate 3-4 of the many scenarios I came across during this phase that can help understand my approach:
How to evaluate whether a large language model is actually better?
I’m usually cautious about single-number metrics. While working on HPT, I’ve seen that model performance depends heavily on task complexity and prompt structure. Thus, I prefer stratified evaluation, measuring performance across difficulty tiers or reasoning depth.
def stratified_eval(model, dataset, buckets):
results = {}
for level, samples in buckets.items():
scores = []
for x in samples:
scores.append(model.evaluate(x))
results[level] = {
“mean”: np.mean(scores),
“std”: np.std(scores),
“worst_case”: np.percentile(scores, 5)
}
return resultsThis avoids over-optimizing for shallow tasks. I look for stability: sensitivity to prompts, variance across seeds, and failure modes. Especially under compute constraints, a slightly worse average model that’s more stable is often preferable. One needs to understand benchmark fragility, not to worship leaderboards, and to care about robustness under constraints (system constraints).
How to decide whether a drop in numerical precision is acceptable? What signals to look for?
There are three things I need here: Do I understand why precision can be lowered? Do I know what can break? Do I validate with signals and not faith? When deciding whether reduced numerical precision is acceptable, I look for both statistical stability and task-level robustness. At a numerical level, I need to analyze activation and weight distributions, for example, using percentile-based ranges, to check whether most values are well-presented at lower precision or if there are heavy tails that would be clipped or destabilized. In practice, I’ve used percentile-based analysis, like focusing on the 5-95% range, to understand how much dynamic range is actually used. If the majority of the signal lies in a stable range, lower precision is usually safe.
def percentile_range(tensor, low=5, high=95):
flat = tensor.detach().cpu().numpy().ravel()
return np.percentile(flat, [low, high])
with torch.no_grad():
for name, param in model.named_parameters():
p5, p95 = percentile_range(param)
if abs(p95 - p5) < threshold:
print(f”{name}: safe dynamic range”)However, this is just a pre-check. The final decision is always task-driven: I need to compare downstream metrics, variance across runs, and sensitivity to input perturbations.
def compare_precision(fp32_model, int8_model, dataset):
metrics = {}
for model_name, model in [(”fp32”, fp32_model), (”int8”, int8_model)]:
scores = [model.run(x) for x in dataset]
metrics[model_name] = {
“mean”: np.mean(scores),
“std”: np.std(scores)
}
return metricsIf reduced precision causes unstable gradients, large variance, or specific failure modes, it’s not acceptable, even if average accuracy looks fine. So for me, precision reduction is acceptable when both the numerical behavior and the system-level outcomes remain stable.
If we have two models: one is slightly accurate but 2x slower, the other is faster but slightly worse, how can I decide which one to deploy ot continue optimizing?
Shall I default to accuracy and not condition this on constraints? Absolutely no! Since I already have my mathematical model, the first thing I’ll check is my constraints, and my decision will depend on the observations from my measurement model. Then, I’ll know if there’s headroom for optimization in the iteration phase. There’s no need to choose immediately. First, I’d check whether the slower model violates any hard constraints (latency, throughput, memory, or cost). If it does, it disqualifies regardless of accuracy. Now, if both models meet constraints, then I look at where the time is going. If the slower model is bottlenecked by something optimizable like memory access, architecture (attention structure), or batch layout, it may be worth pursuing. But if the slowdown comes from fundamental architectural costs (little optimization headroom), I’d favor the faster model and try to recover accuracy through better model calibration. In practice, I’ve found that it’s often easier to improve accuracy than to halve latency, so the faster model is usually the better starting point unless accuracy is mission-critical.
Now, one can ask: how to work with the measurement model to determine whether a model has optimization headroom? By profiling. I’d look at whether the model is compute-bound or memory-bound, examine kernel utilization, and identify dominant costs. If most time is spent in operations that are already efficient or unavoidable, headroom is limited. But if I see memory fragmentation, poor utilization, or redundant computation, that’s a signal that optimization is possible.
A lot of us have experience in training a large language model. Assume that using our “measurement” model, we observe that validation loss improves, but downstream task performance gets worse. What could cause this, and how can one investigate?
This is research judgment, not trivia. There could be several possible reasons, and I’d treat this diagnosis problem rather than a single failure mode. First, validation loss and downstream task performance may be misaligned. The model might be over-optimizing the training objective, for example, next-token prediction, in a way that doesn’t improve task-relevant representations. Second, distributional issues are common. The validation set may be too similar to the training data, while downstream tasks are more out-of-distribution, revealing brittleness. Third, representation collapse or reduced diversity can occur; the model gets better at predicting frequent patterns but loses signal for harder tasks. To investigate, I’d evaluate performance across task difficulty levels, analyze representation similarity, and test robustness to perturbations. I’d also look at whether regularization, data diversity, or evaluation design needs adjustment. Ultimately, improving loss isn’t sufficient unless it translates into better task-level behavior.
Whenever something improves, but behavior worsens, I assume objective misalignment or hidden constraints, and I diagnose before optimizing.
When I stop iterating
Iteration without a stopping criterion is just noise. I stop working on an approach when one of the following conditions is met:
The system violates hard constraints (latency, memory, cost, or reliability), and profiling shows no meaningful optimization headroom.
Improvements in surrogate metrics (loss, accuracy) fail to translate into better task-level or system-level behavior across controlled scenarios.
The remaining gains require disproportionate complexity relative to the expected impact on the overall system.
These criteria prevent me from over-investing in ideas that are locally interesting but globally misaligned.
How I position my research
I am not interested in optimizing models in isolation, chasing single-number benchmarks, or scaling systems without understanding their failure modes. My work sits at the intersection of modeling, measurement, and systems, where performance is defined by behavior under constraints, not by leaderboard rank.
I care about building models that survive contact with hardware, data drift, and real-world uncertainty. If a method cannot be measured, stress-tested, and reasoned about as part of a larger system, I consider it incomplete. This perspective shapes the problems I choose and the way I evaluate progress.
This isn’t a universal framework or a prescription for how research should be done; it’s simply the set of instincts I’ve learned to trust through building systems that had to work.